
大家好,上节课我们分析了生产端用于批量发送消息的暂存类RecordAccumulator,并没有真正的网络IO,真正的网络IO是由Sender类完成的。Sender类是我们学习生产者相关核心类的最后一个,学完它我们就完成了生产者相关类的最后一块拼图,我把消息生产的整体流程以一张流程图的形式介绍给大家,大家可以初步了解一下Sender类的基本功能以及发送消息的处理流程,同时大家还可以和几节课的内容串起来加深理解。我们还是用一个思维导图来概括下今天要讲解的内容。
流程讲解:
我简单解释一下:
Sender的处理流程分两大部分,发送请求和接收响应:
发送请求
发送请求分为两个部分。第一个部分是消息预发送,Sender会从RecordAccumulator拉取要发送的消息集合,封装客户端请求ClientRequest,把ClientRequest类对象发送给NetworkClient。NetworkClient主要有两个工作,首先会根据收到的ClientRequest类对象构造InFlightRequest类对象,InFlightRequest类对象被视为已经发送但响应还没回来的请求。同时根据收到的ClientRequest类对象构造NetworkSend类对象,并放入到KafkaChannel的缓存里,这时消息预发送结束。下一步是真正的网络发送,Sender会调用Selector的poll()方法把请求真正的发送到broker节点。
接收响应
接下来,Selector会收到broker的响应,Sender根据响应会找到对应的请求,然后调用ProducerBatch内的回调方法完成整个发送响应的流程。
好,接下来我们进入源码讲解的环节。
源码讲解
类Sender
Sender类是一个线程类,主线程创建并被标识为后台线程。
字段
下面是类Sender的重要字段的源码,我会给大家详细讲解
public class Sender implements Runnable {
private final KafkaClient client;//管理网络连接,操作网络读写
private final RecordAccumulator accumulator;//消息积聚器
private final ProducerMetadata metadata;//生产者的元数据
private final boolean guaranteeMessageOrder;//是否保证消息在服务端的顺序性
private final int maxRequestSize;//向服务端生产消息时,最大请求字节数。
private final short acks;//producer的消息发送确认机制
private final int retries;//发送失败后的重试次数。默认是0次
private volatile boolean running;//Sender线程是否还在运行中
private final int requestTimeoutMs;//等待服务端响应的最大时间。默认30s
private final long retryBackoffMs;//失败重试退避时间
private final ApiVersions apiVersions;//所有node支持的api版本。
private final Map
client:KafkaClient类型,是一个接口,Sender具体用的是KafkaClient接口的实现类NetworkClient。这个字段为Sender提供了网络连接管理和网络读写操作的功能。accumulator: RecordAccumulator类型。即上节课我们讲的RecordAccumulator类的对象。Sender利用它获取待发送的node和待发送的消息等功能。metadata: ProducerMetadata类型,MetaData接口的实现类。生产者元数据。发送消息时要知道分区leader在哪些节点,以及节点的地址,主题分区的情况等。MetaData接口对应的还有消费者元数据类,我们讲到消费者部分的时候会讲到。guaranteeMessageOrder:bool类型。是否保证消息在服务端的顺序性。maxRequestSize: int类型。。请求的最大字节数,默认值是1M。该设置将限制生产者在单个请求中发送的记录次数,以避免发送大量请求。acks:short类型。producer的消息发送确认机制。ack有3个可选值,分别是1,0,-1。默认值-1。我分别给大家介绍一下3个值的含义:
1)ack=1,producer只要收到一个副本成功写入的通知就认为推送消息成功了。这个副本必须是leader副本。只有leader副本成功写入了,producer才会认为消息发送成功。
2)ack=0,producer发送了就任务发送成功,不管是否发送成功。
3)ack=-1,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
retries:int类型。生产者发送失败后的重试次数。默认是0次。running:bool类型。Sender线程是否还在运行中。requestTimeoutMs: int类型。默认值30,000,即30秒。生产者发送请求后等待服务端响应的最大时间。过了最大响应时间如果配置了重试,生产者会再次发送这个请求。重试用完还在这个时间内返回响应则认为是请求失败。retryBackoffMs: long类型。默认是100。生产者发送请求失败后可能会引起重新发送失败的请求,这个参数的目的是防止重发过快造成服务端压力过大。apiVersions: ApiVersions类的对象,内部保存了每个node支持的api版本。inFlightBatches:发送中请求的Map集合。分区是Key,List是value。
方法:
runOnce()
void runOnce() {
......忽略
long currentTimeMs = time.milliseconds();
//1.发送消息到KafkaChanel缓存
long pollTimeout = sendProducerData(currentTimeMs);
//2.发送消息到网络
client.poll(pollTimeout, currentTimeMs);
}
runOnce()被Sender线程run()方法调用,而且字段running为true的情况下run()方法会一直轮询调用runOnce()。这个方法很简单首先获取当前时间戳。然后调用sendProducerData()方法发送消息,但这里的发送不是真正的发送,只是把消息作为缓存保存在NetworkClient的send字段里。最后调用NetworkClient的poll()方法读取send字段内容实现真正的网络发送。NetworkClient的poll()方法的调用在07课程已经讲了,这里就不再讲解了,主要主要讲讲sendProducerData()方法。
sendProducerData(long now)
这个方法主要是在发送前对要发送的消息进行收集,过滤,然后调用真正的消息发送方法,最后返回poll()方法的超时时间。现在看一下源码:
//消息发送到暂存类中,并返回poll超时时间。
// 因为send和poll在一个线程中,poll的
// 超时时间过长可能会造成不能及时send消息
private long sendProducerData(long now) {
//1.获取元数据
Cluster cluster = metadata.fetch();
//2.请求已经准备好的节点
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//3.如果任何leader分区不存在,就要求更新元数据
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// remove any nodes we aren't ready to send to
//4.在result返回的node集合的基础上再检查客户端和node连接是否正常。
Iterator
batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
accumulator.resetNextBatchExpiryTime();
//6.收集过期的batch
//Sender自定义inflightBatches集合里过期的batch
List
expiredInflightBatches = getExpiredInflightBatches(now);
//accumulator定义的batches集合里过期的batch
List
expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
//7.处理过期batch
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, -1, NO_TIMESTAMP, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
//8.发送消息
sendProduceRequests(batches, now);
return pollTimeou
我把方法执行的步骤给大家讲解一下:
获取元数据。元数据根据更新机制会近实时的保证数据的准确性。调用accumulator的ready()方法,这个方法会用发送记录对应的节点和元数据作比较,方法返回包括两个重要的集合,包括: readyNodes: 准备好发送的节点集合。unknownLeaderTopic:找不到某个leader分区的主题。如果任何leader分区不存在,就要求更新元数据。检查readyNodes集合里的node和客户端的网络连接连接是否正常。NetworkClient类维护了客户端和所有node的连接,这样根据连接的状态来判断连接是否是正常的。获取要发送的请求集合。accumulator.drain()方法会返回把按分区收集的请求集合转换为按节点收集的请求集合,Map,为什么Sender要做这个集合的转换呢?我下面给大家解释一下,如下图所示:
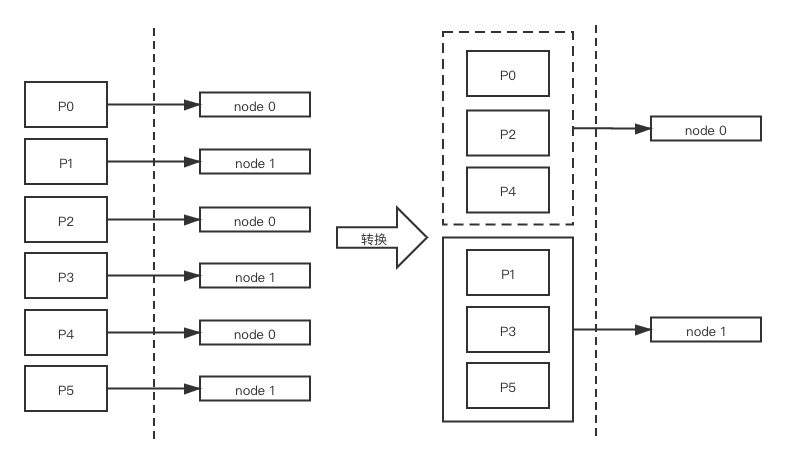
假设有两台服务端机器,一个主题有6个分区,每台机器有3个分区。如果按照分区发送就会有6个请求,而按节点发送总共就有两个请求。按节点发送可以大大减少网络的开销。
- 收集和处理过期的批次。在有些情况下,消息很久都没发送出去,我们不可能让消息批次一直等待,要有对应的超时批次的处理逻辑。先看下详细代码:
private List
getExpiredInflightBatches(long now) {
//1.创建过期批次集合
List
expiredBatches = new ArrayList<>();
//2.遍历inFlightBatches
for (Iterator>> batchIt = inFlightBatches.entrySet().iterator(); batchIt.hasNext();) {
Map.Entry> entry = batchIt.next();
List
partitionInFlightBatches = entry.getValue();
if (partitionInFlightBatches != null) {
Iterator
iter = partitionInFlightBatches.iterator();
//3.遍历某个分区的生产者批量发送列表
while (iter.hasNext()) {
ProducerBatch batch = iter.next();
//4.判断batch是否投递超时。默认消息投递过期时间是2 minutes
if (batch.hasReachedDeliveryTimeout(accumulator.getDeliveryTimeoutMs(), now)) {
//5.删除投递过期的batch
iter.remove();
//6.如果 batch 没有最终的状态,就把batch加入到expiredBatches集合
if (!batch.isDone()) {
expiredBatches.add(batch);
} else {
throw new IllegalStateException(batch.topicPartition + " batch created at " +
batch.createdMs + " gets unexpected final state " + batch.finalState());
}
} else {
//更新下一个Batch的超时时间。
accumulator.maybeUpdateNextBatchExpiryTime(batch);
break;
}
}
if (partitionInFlightBatches.isEmpty()) {
batchIt.remove();
}
}
}
return expiredBatches;
}
首先创建过期批次的集合expiredBatches,然后遍历inFlightBatches,拿到分区对应的List
后,再遍历List
,如果发现ProducerBatch存留的时间超过accumulator.getDeliveryTimeoutMs()就认为该批次过期了,DeliveryTimeoutMs的默认值是120s。如果发送的消息很多而且不太在意消息的延迟,可以考虑把这个参数适当增加。对于过期的批次,会从inFlightBatches里删除。
- 处理过期的批次。
通过调用failBatch()方法实现对过期批次的处理,然后把过期的批次放入expiredBatches集合里。
//失败batch的处理
private void failBatch(ProducerBatch batch,
long baseOffset,
long logAppendTime,
RuntimeException exception,
boolean adjustSequenceNumbers) {
if (transactionManager != null) {
transactionManager.handleFailedBatch(batch, exception, adjustSequenceNumbers);
}
this.sensors.recordErrors(batch.topicPartition.topic(), batch.recordCount);
//超时调用回调
if (batch.done(baseOffset, logAppendTime, exception)) {
maybeRemoveAndDeallocateBatch(batch);
}
}
这个方法最关键的是代码13行里调用batch.done()。具体是调用了batch里的回调方法。也就是说对于超时的批次不会发送给服务端了,而是直接执行回调方法完成请求。执行成功后删除批次并释放批次占用的空间。
- 调用sendProduceRequests(batches, now)。我们看下这个方法:
private void sendProduceRequests(Map> collated, long now) {
for (Map.Entry> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}
本质上是轮询过滤完的批次集合去调用sendProduceRequest()方法,因为key是节点所以每调用一次就是向某个节点发送请求,而且是批量的发送因为value是List
。下面我们来介绍sendProduceRequest()方法,源码如下:
/**
* Create a produce request from the given record batches
* 把ProducerBatch类型转换成ClientRequest,并把clientRequest放到KafkaChannel的缓存里。
*/
private void sendProduceRequest(long now, int destination, short acks, int timeout, List
batches) {
if (batches.isEmpty())
return;
//1.初始化两个集合,produceRecordsByPartition用于构建请求,recordsByPartition用于构建回调方法
Map produceRecordsByPartition = new HashMap<>(batches.size());
final Map recordsByPartition = new HashMap<>(batches.size());
......忽略
//2.按分区填充produceRecordsByPartition和recordsByPartition两个集合。
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
......
//3.创建requestBuilder对象。
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
//4.创建回调
RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());
String = Integer.toString(destination);
//5.创建clientRequest
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
//6.把clientRequest发送给NetworkClient,完成消息的预发送。
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
第一步,初始化两个集合,produceRecordsByPartition用于构建请求,recordsByPartition用于构建回调。
第二步,按分区填充这两个集合。
第三步,创建requestBuilder对象,。
第四步,创建callback对象。实际上是实例化回调接口RequestCompletionHandler,接口RequestCompletionHandler就一个方法onComplete(),callback对onComplete()的实现方式是用返回的response当参数调用handleProduceResponse()方法。消息发送的时候不会把callback方法发送到服务器,而是把callback放在NetworkClient里等待响应回来后根据响应调用callback。
第五步,创建clientRequest。用produceRecordsByPartition集合构建clientRequest,也就是说一个clientRequest对象里有多个消息批次。
第六步,把clientRequest交给NetworkClient,NetworkClient会调用相关方法把,clientRequest保存在kakfaChannel的send字段里,也就是是说预发送的最小单位是一个List
,也就是一个批次集合,而真正能不能一次就发送一个批次要看当时的网络环境。好,到这里完成消息的预发送。
发送消息设计到的类和方法给大家介绍完了,现在给大家介绍收到响应后Sender线程是如何处理的。
handleProduceResponse(ClientResponse response, Map batches, long now)
/**
* Handle a produce response
* 处理服务端发来的response。
*/
private void handleProduceResponse(ClientResponse response, Map batches, long now) {
RequestHeader requestHeader = response.requestHeader();
int correlationId = requestHeader.correlationId();
//连接失败
if (response.wasDisconnected()) {
log.trace("Cancelled request with header {} due to node {} being disconnected",
requestHeader, response.destination());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now);
//处理版本不匹配
} else if (response.versionMismatch() != null) {
log.warn("Cancelled request {} due to a version mismatch with node {}",
response, response.destination(), response.versionMismatch());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now);
//处理正常响应
} else {
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
// 有响应
if (response.hasResponse()) {
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
for (Map.Entry entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
ProducerBatch batch = batches.get(tp);
//调用completeBatch()方法处理。
completeBatch(batch, partResp, correlationId, now);
}
this.sensors.recordLatency(response.destination(), response.requestLatencyMs());
} else {
//无响应,ack=0时的处理
for (ProducerBatch batch : batches.values()) {
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now);
}
}
}
}
一个响应是某一个节点发给客户端的,一个节点每次向客户端发送的响应也是批量的,一个响应就有可能包含多个分区的响应信息。我们还要调用回调方法告诉生产者发送结果,而回调方法并没有在响应里,这要求我们要从请求的batch集合里拿到回调方法。于是,前面定义的recordsByPartition集合在处理响应的时候就有用了。
客户端接到响应后会根据响应的结果分情况处理:
处理方法是completeBatch(),只是根据具体情况配置的参数不同。
首先会处理两个失败的场景:如果连接失败会设定异常Errors.NETWORK_EXCEPTION,客户端和服务端api版本不匹配会设定异常Errors.UNSUPPORTED_VERSION。
正常响应也分两种情况,有返回值的响应和无返回值的响应。
1) 响应有返回值。根据响应集合里的分区找到recordsByPartition集合里对应的batch,然后把batch和响应信息当参数调用completeBatch()方法。
2)对应响应无返回值。的场景是,当发送时设定的ack=0时,生产端只管发送而不去管响应结果,所以不用考虑响应的返回值,也是调用completeBatch()方法。
好,最终还是要调用completeBatch()方法。我们下面看一下completeBatch()方法。
completeBatch():
方法源码如下:
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId,
long now) {
Errors error = response.error;
//单调消息过长的消息,会把单条消息分成多个batch发送。
if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 && !batch.isDone() &&
(batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {
log.warn(
"Got error produce response in correlation id {} on topic-partition {}, splitting and retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts(),
error);
if (transactionManager != null)
transactionManager.removeInFlightBatch(batch);
this.accumulator.splitAndReenqueue(batch);
maybeRemoveAndDeallocateBatch(batch);
this.sensors.recordBatchSplit();
} else if (error != Errors.NONE) {
//能否再次发送
if (canRetry(batch, response, now)) {
log.warn(
"Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts() - 1,
error);
//再次入对
reenqueueBatch(batch, now);
//重复发送
} else if (error == Errors.DUPLICATE_SEQUENCE_NUMBER) {
//序列化重复的处理
completeBatch(batch, response);
} else {
final RuntimeException exception;
//主题没有权限
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
exception = new TopicAuthorizationException(Collections.singleton(batch.topicPartition.topic()));
//集群没有权限
else if (error == Errors.CLUSTER_AUTHORIZATION_FAILED)
exception = new ClusterAuthorizationException("The producer is not authorized to do idempotent sends");
//直接返回响应的错误信息
else
exception = error.exception(response.errorMessage);
failBatch(batch, response, exception, batch.attempts() < this.retries);
}
//无效的元数据异常
if (error.exception() instanceof InvalidMetadataException) {
//无对应主题或分区的异常
if (error.exception() instanceof UnknownTopicOrPartitionException) {
log.warn("Received unknown topic or partition error in produce request on partition {}. The " +
"topic-partition may not exist or the user may not have Describe access to it",
batch.topicPartition);
//其它元数据异常,直接返回响应的错误信息。
} else {
log.warn("Received invalid metadata error in produce request on partition {} due to {}. Going " +
"to request metadata update now", batch.topicPartition, error.exception(response.errorMessage).toString());
}
metadata.requestUpdate();
}
} else {
//正常执行回调
completeBatch(batch, response);
}
// Unmute the completed partition.
if (guaranteeMessageOrder)
this.accumulator.unmutePartition(batch.topicPartition);
}
首先,我们分析一下各种异常的处理:
- 单调消息过长的异常。需要同时满足四个条件:
1)响应返回MESSAGE_TOO_LARGE异常。
2)batch中只有一条消息
3) batch没有完成。
4)消息的格式大于等于V2版本或消息是压缩的。
满足条件后进入if语句,因为消息太长了就分成多个批次发送,然后从集合中删除此batch,最后释放暂存器里此batch占用的空间。
- 能再次入队等待发送的异常。只要满足canRetry()方法就可以再次尝试发送。canRetry()方法代码在下面,我给大家讲解一下:
canRetry()
private boolean canRetry(ProducerBatch batch, ProduceResponse.PartitionResponse response, long now) {
return !batch.hasReachedDeliveryTimeout(accumulator.getDeliveryTimeoutMs(), now) &&
batch.attempts() < this.retries &&
!batch.isDone() &&
(transactionManager == null ?
response.error.exception() instanceof RetriableException :
transactionManager.canRetry(response, batch));
}
要同时满足四个条件,才能重新发送:
- 没有到投递的超时时间。
- batch重试次数没超过设定的次数。
- 批次没结束。
- 如果不被事务管理响应的异常属于可重试的异常,如果被事务管理调用事务管理器自定义的判断器判断是否能重试。
- 序列化重复的异常。说明消息重复发送了,不用做任何处理。
- 主题没有权限的异常。集群没有权限的异常。已经其他异常,统一调用方法failBatch()处理。
- 元数据的异常。包括找不到对应分区及其它的元数据异常。这两个异常除了打印对应的异常日志都会设定元数据需要更新的标识,因为响应已经报元数据异常了就应该及时更新元数据。
- 响应没有异常。调用completeBatch(batch, response)完成响应处理。
接下来我们讨论处理正常响应的方法completeBatch(batch, response):
completeBatch(batch, response)
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response) {
if (transactionManager != null) {
transactionManager.handleCompletedBatch(batch, response);
}
//执行回调,并释放 accumular 的空间
if (batch.done(response.baseOffset, response.logAppendTime, null)) {
maybeRemoveAndDeallocateBatch(batch);
}
}
这个方法就两个部分,调用batch的done()方法,然后从集合中删除batch并释放batch占用的内存。
好了,到目前为止,Sender类从发送消息到处理响应的主要方法都分析完了。现在总结一下今天学习的知识点。
总结:
Sender类是一个线程类,如果不主动关闭Sender会一直执行下去。我们讲解了Sender处理消息的流程,包括消息的发送和消息的响应处理。消息的发送还包括消息预发送和真正的网络发送。我们分析了Sender类的相关字段和方法。Sender类用到了很多其他组件,包括NetworkClient用于网络IO,RecordAccumulator用于获取要发送的消息。MetaData用于获取元数据。sendProducerData及相关方法用于消息的预发送。调用NetworkClient类的poll()方法用于真正的网络发送。completeBatch()方法包含了各种异常响应和正常响应的处理。handleProduceResponse()方法是回调方法的处理逻辑。






